In today’s enterprise world, where we can obtain servers with hundreds of CPU cores and terabytes of RAM, it may seem surprising that we could still encounter limitations in the event aggregation process.
As we recently discussed, when the data being aggregated is critical and cannot be lost due to hardware outages, it’s not enough to store aggregated events in memory alone. Persistent storage solutions, such as NVMe drives, are required to preserve the data throughout all stages of processing.
When you look at benchmarks for modern NVM drives (especially PCIe Gen 5), the numbers are impressive – up to 12 gigabytes per second read/write for large files. However, these numbers are less impressive when dealing with small files. When operating with databases and events (which are typically a few kilobytes or less), you’re often working with small block sizes – around 4-8 KB. This is why you will rarely see write speeds in the multi-gigabyte per second range during database record updates.
Let’s try to translate disk performance into the number of database operations (updates and inserts) per second. For example, if I want to maintain a constant performance level of 100K aggregated event records per second, the application should be able to execute 100K queries (one read for each new event) and then either insert a new record or update an existing one, resulting in an additional 100K write operations. If the size of each event is less than 4 KB, this would generate around 400 MB/s of raw data for disk writes. In reality, you will see even more writes due to various overheads caused by the database and file system, potentially reaching up to 1 GB/s, assuming IO deficit is not an issue for your modern drive and it can sustain such performance.
How long can your drive survive with constant 1 GB/s writes? It depends on the specific drive’s endurance, but let’s try to estimate. Over the course of one day, approximately 84 TB will be written. With the endurance of an average enterprise drive (TBW or total bytes written) at 20 PB, it could last about 240 days. A consumer-grade drive, on the other hand, would fail within 2-3 weeks.
Therefore, you need to consider all possible optimizations to minimize writes and distribute them wisely across physical drives, as we do in our TriceMate mediation. Of course, don’t forget about RAID to protect your data!
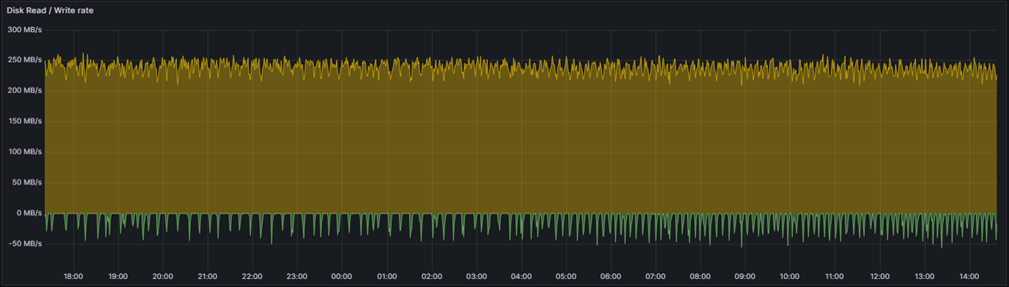
As you can see, there are many caveats here. By the way, we haven’t discussed how the CPU can be a bottleneck. Maybe next time… P.S. The chart at the beginning of the post represents disk writes/reads with efficient caching and application performance of ~54K RPS.