What is TricePorter?
TricePorter is a versatile file transfer automation tool featuring a flexible scheduling system and support for SFTP and S3 protocols. It can run as a portable binary on the most popular operating systems, handling all these tedious tasks for you—including compressing files on the fly and storing them in daily directories. It was developed to reduce overhead which is coming to the picture when some automated transfer flows need to be established. In other words, it’s very useful when you need to pull/push/archive files based on some predefined schedule or constantly in real time. You no longer need to repeat annoying manual steps again and again which is great!
Automation here is first priority and all other bells and whistles are secondary, so do not be surprised to not find them in our app. We are considering expanding the scope based on feedback from the community, so some functions which you personally classify as important might be included into further versions of TricePorter. We’ll be happy to see your feedback in our Blog, X, Reddit, Linkedin.
We believe that it is very important to have our tool to be cross-platform and available on major operational systems. So, we are trying to keep scope clean with only reasonably useful features, otherwise maintaining distributives for different platforms might turn into a nightmare.
High level overview
Please review the diagram below which can give an idea on how TricePorter is working. This is example of random setup with SFTP and S3 destinations.
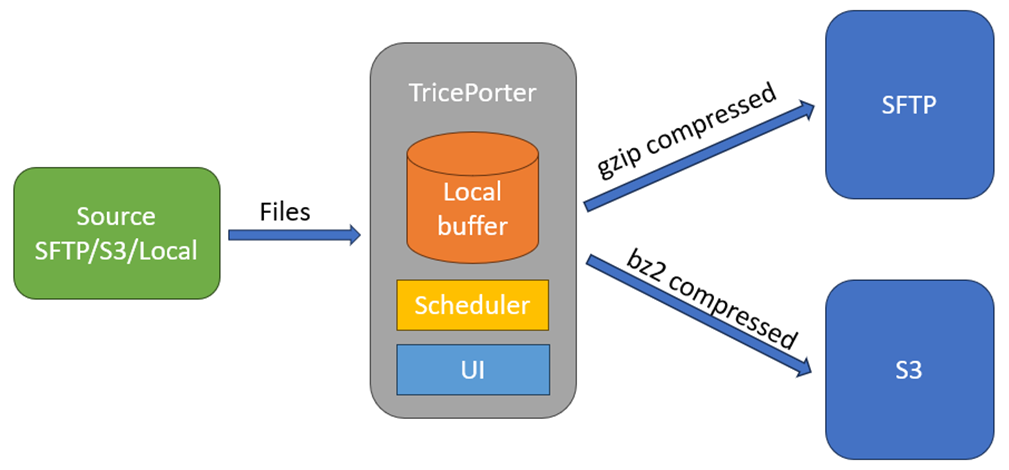
Files are coming from the source and could be distributed into multiple different locations. You can do it manually or you can use scheduling option, compress/uncompress files on the fly, put them into daily directories, etc.
The most important thing to remember that files are being transferred in two steps:
Step 1: Files are coming to the local buffer first. Local buffer is located in the same directory as a TricePorter binary ./appdata/buffer/<Name_of_destination>.
Step 2: Then files from the local buffer are being transferred into destinations. Buffer will be cleared when the file will be successfully transferred.
If you have the flag “Delete file after collection” set in “Yes”, then the file will be deleted from the source once it will be successfully downloaded into the local buffer. If you will have some issues with distribution (for example, SFTP credentials will not work properly) then your file will be safely stored in the buffer until the issue will be resolved. If it will not be resolved soon and you need your file, then you can pull it from the buffer manually.
Installation
Trice porter is available as a portable binary for the following 64bit platforms: Linux, MacOS, Windows. Also, for the better resource control you might want to consider using containerized version of TricePorter.
The best aspect of TricePorter is its ease of use – simply download the binary file, run it, and connect to the UI using http://localhost:18090. From there, you can easily adjust the configuration to suit your needs. Once TricePorter is up and running, automated file transfers are seamlessly initiated
TricePorter for Linux
Download file to any convenient location.
triceporter-1.1.0-linux-amd64.gz
Gunzip and give executable permissions:
gunzip triceporter-1.1.0-linux-amd64.gz
chmod +x triceporter-1.1.0-linux-amd64
Start the executable file
To open UI go to the following link in the browser: http://localhost:18090
TricePorter for Linux — older x86-64 CPU’s
This version of TricePorter is recommended for the systems with the older hardware (pre-haswell era).
Download file to any convenient location.
triceporter-1.1.0-linux-amd64-pre-haswell.gz
Gunzip and give executable permissions:
gunzip triceporter-1.1.0-linux-amd64-pre-haswell.gz
chmod +x triceporter-1.1.0-linux-amd64-pre-haswell
Start the executable file
To open UI go to the following link in the browser: http://localhost:18090
TricePorter for MacOS
Download file to any convenient location
triceporter-1.1.0-darwin-arm64.gz
MacOS x86_64 version is coming soon…
Gunzip and give executable permissions:
gunzip triceporter-1.1.0-darwin-arm64.gz
chmod +x triceporter-1.1.0-darwin-arm64
Start the executable file
To open UI go to the following link in the browser: http://localhost:18090
TricePorter for Windows
Download and unzip the file to any convenient location
triceporter-1.1.0-windows-amd64.zip
Start the executable file
To open UI go to the following link in the browser: http://localhost:18090
TricePorter for Docker
Currently we have two versions of TricePorter on DockerHub:
- apptrice/triceporter — this version is appropriate for the most Linux and Windows users with modern hardware
- apptrice/triceporter-legacy — this version is for users with older CPU’s (pre-haswell) and all MacOS users which would prefer to use docker instead of binary executable. Please make sure that virtualization is enabled in Docker desktop tool if you are using ARM M1, M2, M3 Apple CPU’s.
Native ARM docker image is coming soon...
To run TricePorter and have UI exposed to port 18090 please run:
docker run -p 18090:18090 apptrice/triceporter
If you want to have your TricePorter configuration and buffer persistent after container restart, then you might use the following:
docker volume create triceporter_volume
docker run --mount type=volume,src=triceporter_volume,target=/opt/triceporter -p 18090:18090 apptrice/triceporter
New Docker volume triceporter_volume will be created and used to store TricePorter buffer and configuration.
To check the exact location of this volume please use command:
docker volume inspect triceporter_volume
...
"Mountpoint": "/var/lib/docker/volumes/triceporter_volume/_data",
TricePorter for Docker — older x86-64 CPU’s and MacOS
To run TricePorter-legacy and have UI exposed to port 18090 please run:
docker run -p 18090:18090 apptrice/triceporter-legacy
If you want to have your TricePorter configuration and buffer persistent after container restart, then you might use the following:
docker volume create triceporter_legacy_volume
docker run --mount type=volume,src=triceporter_legacy_volume,target=/opt/triceporter -p 18090:18090 apptrice/triceporter-legacy
New Docker volume triceporter_legacy_volume will be created and used to store TricePorter buffer and configuration.
To check the exact location of this volume please use command:
docker volume inspect triceporter_legacy_volume
...
"Mountpoint": "/var/lib/docker/volumes/triceporter_legacy_volume/_data",
TricePorter Configuration
TricePorter could be configured using simple UI in browser or by modification of config file, whatever is more convenient for you.
Configuration file is located in the same directory as a binary ./appdata/config/config.json. If config file will be missing in this location, then some default configuration with local destinations will be loaded and file will be autogenerated after binary execution.
While the configuration file is relatively self-explanatory in JSON format, we recommend familiarizing yourself with the user interface for quicker and easier implementation of minor changes.
TricePorter UI review
To get to UI, please type http://localhost:18090 in the browser and hit enter. You will be redirected to the login screen.
You will be asked to type admin password which is ‘admin’ by default after the very first run and could be changed to your own supersecret.
This is how UI look when you logged in.
—
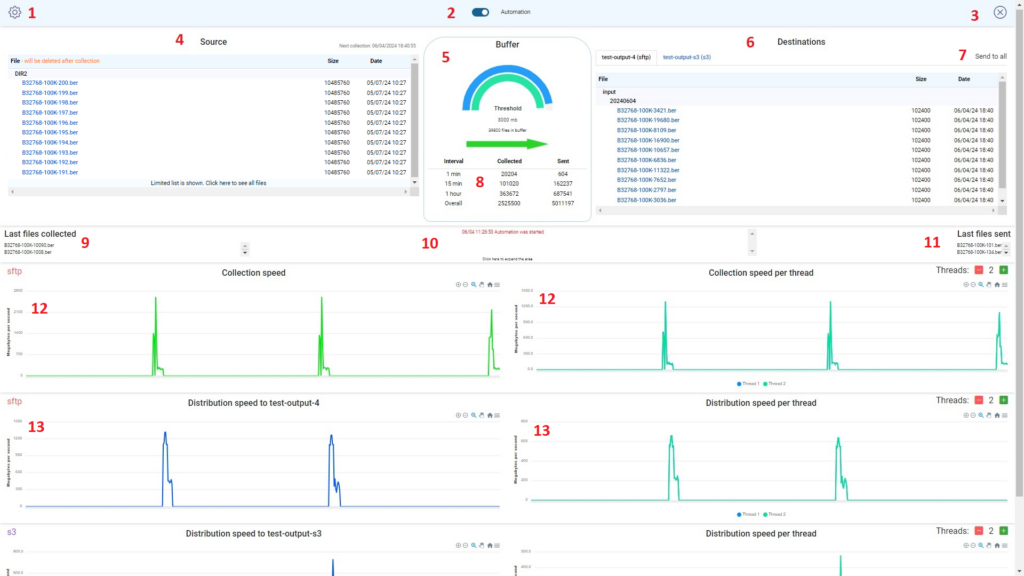
Here the brief summary of control elements on the main page:
- Settings – in this menu you can configure source, destinations, schedule and other important parameters. See detailed explanation here.
- Automation on/off – this switch enables automated file transfer, according to a defined schedule. When automation is turned off, you are still able to transfer files manually using drag and drop.
- Stop application – apparently stopping application.
- Source – in this panel you can see the content of the “input” directory on the source.
- Buffer + threshold – here you can see a representation of the volume of files which are pending in the buffer and about to be transferred to the destinations. Threshold value is used for better visibility, you can adjust it in the configuration menu. You might want to keep it less if you are mostly transferring small files and bigger in case of huge files. Please note, it is possible to see values more than 100% and this is legitimate behavior. Threshold is for informative purposes only and will not prevent collecting more files from the source even if the buffer is shown as 100% full. However, there is another option to limit the number and size of files in the buffer which could be defined in the configuration menu and collection from the source will be on hold when values will cross one of those limits. Also, in this section you can see the oldest file currently in the buffer, but it will be displayed only if it is at least 5 minutes old.
- Destinations – in this panel you can see the content of the “output” directory on the destinations.
- Send to all – use this field when you want to drag-n-drop your file to all existing destinations in one go.
- Statistics “Last collected/sent” – this statistic represents the number of files which were sent during the last 1 min, 15 min, 1 hour, 1 day. These counters will be reset if TricePorter is restarted.
- Last files collected – several last files which were collected.
- Alerts – major events and alerts will be shown here in red, i.e. problem with connectivity, errors in transfer, start/stop automation etc.
- Last files sent – several last files which were sent.
- Collection speed – on the left side you can see a chart which represents total collection speed. On the right side you can see speed per each thread.
- Distribution speed – on the left side you can see a chart which represents total distribution speed. On the right side you can see speed per each thread. You should see the same number of charts, as many destinations you have.
Menu Settings in UI
You will be redirected to the settings of source when you are clicking on the gear icon in the upper left corner
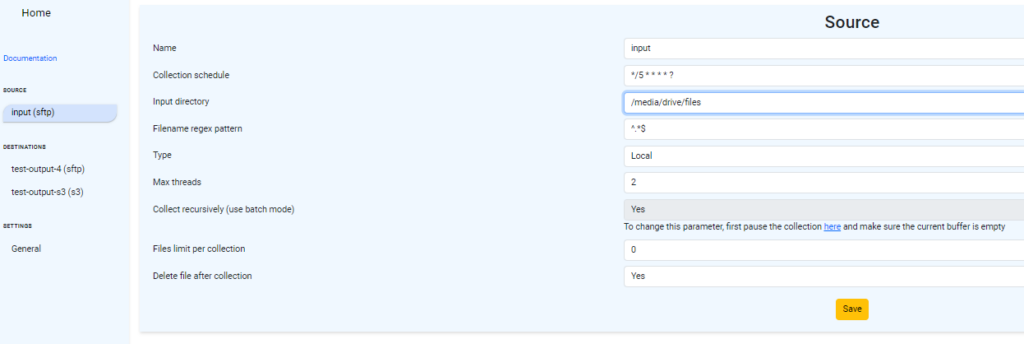
—
- Name – it’s just a name of your feed, you can use any definition of the location from which you want to collect files. Please avoid using non-alphanumeric values.
- Collection schedule – cron like scheduler with precision 1 sec.
- Cron-Expressions are strings that are actually made up of seven sub-expressions, that describe individual details of the schedule. These sub-expression are separated with white-space, and represent:
- Seconds, Minutes, Hours, Day-of-Month, Month, Day-of-Week, Year (optional field)
- In a cron, both ‘?‘ and ‘*‘ are used as wildcards, but they have different meanings. ‘*‘ stands for “every” or “any value” within the allowed range for a particular field. ‘?‘ is used specifically in the day of the week and the day of the month fields. It means “don’t care” or “no specific value.” It allows you to specify one of these fields while leaving the other as a wildcard.
- An example of a complete cron-expression is the string “0 0 12 ? * WED” – which means “every Wednesday at 12:00:00 pm”.
- Want to have a file collection running every 5 minutes? “0 */5 * * * ?“
- Need to send files once a day at 2 PM? “0 0 14 * * ?“
- Input directory – from this path on the source you are going to pick your files
- Filename regex pattern – REGEX like file pattern for collection. Please refer to any regular expression tutorial or article if you need more details. If you would like to collect all files, then you can also use * as a parameter, it will be automatically converted to regex.
- Type – here you should chose the type of connection which you are going to use, It might be either local, SFTP or S3 (object storage Amazon of self-hosted, like MinIO). Please see more details about SFTP and S3 configuration parameters below.
- Max Threads – how many threads will be used for file transfer (limited to 2 in the current version).
- Collect recursively (use batch mode) – this option is allowed to collect recursively files embedded into directories and subdirectories. The same dir/file structure will be created on the destinations. Max depth of recursion is 100. Please note, drag and drop feature in UI will not work if this parameter is “Yes”.
- Files limit per collection – how many files you want to collect after each timer execution. By default, value is “0”, i.e. not limited.
- Delete file after collection – set this parameter to “Yes” if you want to remove automatically files from the source when file will be collected. Please refer to high level overview above to get better idea how files will be processed in steps.
Destinations could be added, removed or re-configured
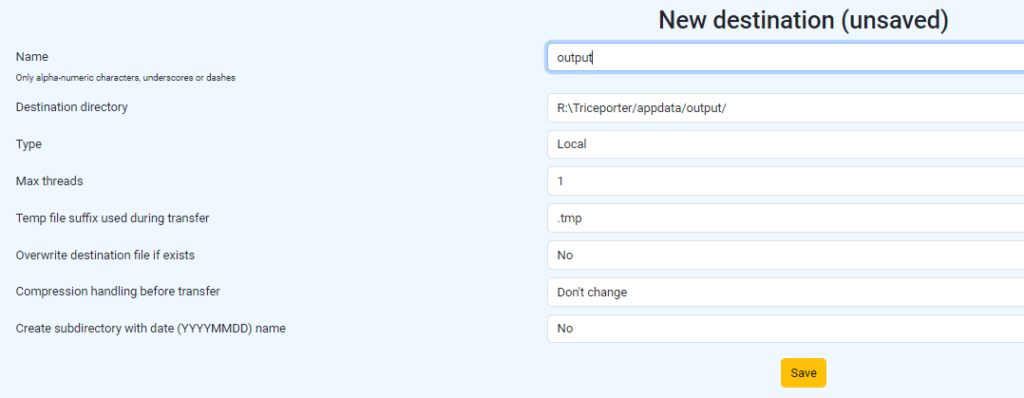
—
- Name – it’s just a name of your destination, you can use any definition of the location where you want to send files. Please avoid using non-alphanumeric values.
- Destination directory – path on the destination where files should be transferred.
- Type – here you should chose the type of connection which you are going to use, It might be either local, SFTP or S3 (object storage Amazon of self-hosted, like MinIO). Please see more details about SFTP and S3 configuration parameters below.
- Max Threads – how many threads will be used for file transfer (limited to 2 in the current version).
- Temp file suffix used during transfer – files will be transferred with this temporary suffix and renamed on destination after transfer
- Overwrite destination file if exists – files will be overwritten on the destination if “Yes”. If “No”, then files with the same names will go to the “duplicates” directory located next to TricePorter binary ./appdata/duplicates/<name_of_destination>
- Compression handling before transfer – You can select the compression method here. You have the options to compress files using gzip and bzip2. Additionally, you can choose to decompress files if they are in gzip or bzip2 format. Please note that if you select bzip2 for this parameter and the files are in gzip format, they will be uncompressed first and then compressed using bzip2. In other words, if the file appears as XXX.gz, you will receive XXX.bz2 instead of XXX.gz.bz2, ensuring compression occurs only once
- Create subdirectory with date (YYYYMMDD) name – You have the option to create a daily directory at the destination and place files into it. This feature can be useful if you’re looking to establish an archive.
SFTP parameters for source or destinations look like this
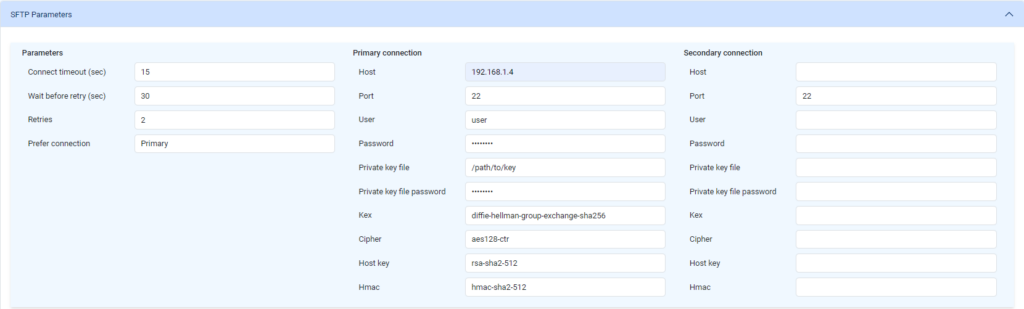
- Connect timeout (sec) – how long to wait while trying to connect to the host
- Wait before retry (sec) – it attempt to connect was not successful, wait as many seconds before retry
- Retries – how many times to try to connect before trying another host (if configured)
- Prefer connection – which SFTP host is preferred, primary or secondary
- Host – DNS name or IP address of SFTP host
- Port – port where SFTP server is running on SFTP server
- User – username
- Password – password of user above. Stored encrypted, you will not be able to see it when saved.
- Private key file – path to private key if using passwordless connection
- Private key file password – password of private key (if exists). Stored encrypted, you will not be able to see it when saved
- Kex – preferred Kex. Keep empty for default
- Cipher – preferred Cipher. Keep empty for default
- Host key – preferred host key. Keep empty for default
- Hmac – preferred Hmac. Keep empty for default
- Secondary connection – (optional) alternative SFTP host which could be used for a file transfer if primary is not available
S3 parameters for source or destinations look like this
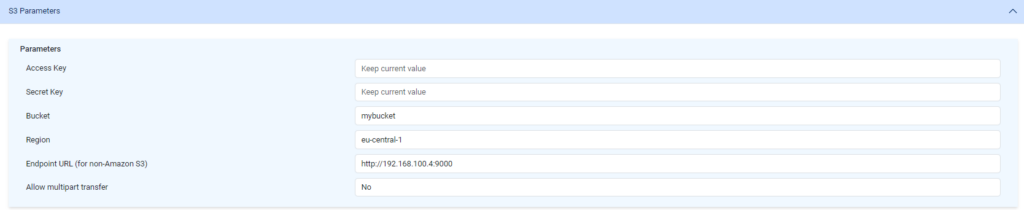
- Access Key – Access key for your Amazon or self-hosted S3
- Secret Key – Secret key for your Amazon or self-hosted S3
- Bucket – S3 bucket
- Region – Amazon S3 region, keep it empty for self-hosted S3
- Endpoint URL (for non-Amazon S3) – this is URL to your self-hosted S3 server
- Allow multipart transfer – If set to ‘Yes’, the file will be downloaded in multiple small pieces in parallel, which will then be combined. This approach can be beneficial for long-distance transfers and channels with inconsistent bandwidth. “No” is recommended default value.
General settings
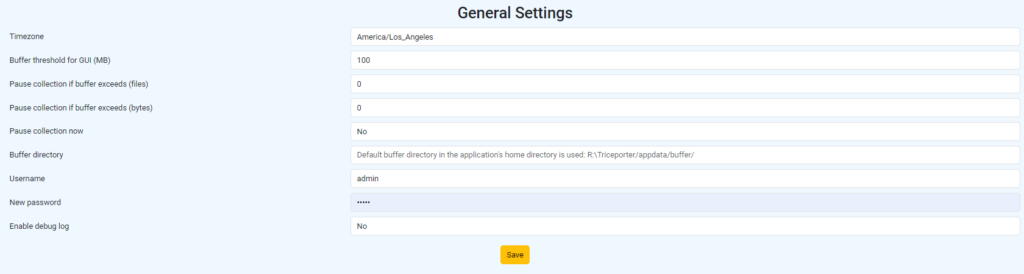
—
- Timezone – you can specify your preferred timezone here
- Buffer threshold for GUI (MB) – this value is for better visualization of the buffer utilization. You might want to keep it less for small files and increase for bigger. Please note, this value is for better visualization only, it will not impact buffer limits
- Pause collection if buffer exceeds (files) – pause collection if buffer contains as many files. By default not limited, value “0”
- Pause collection if buffer exceeds (bytes) – pause collection if buffer contains files with total volume as many bytes. By default not limited, value “0”
- Pause collection now – using this parameter you can pause file collection if needed
- Buffer directory – here, you can specify your preferred location for the buffer. For instance, if your system has multiple drives, you may opt for a faster or more durable drive
- Username – this username for UI access only
- New password – here you can update default UI password which is “admin”
- Enable debug log – here, you can activate the debug log. This feature provides detailed information in case of errors or if you simply wish to gain a better understanding of the steps and timings involved during file transfers at each stage. Please note that the log file may grow rapidly during intensive file transfers and could potentially impact performance, especially when dealing with small files
—